医療データベース研究②(研究の概要)
-
医療データベース自主研究報告続きです。
本稿では研究の概要について報告します。(前回まで)
医療データベース研究①研究デザインは
「医療情報データベースを用いたコホート研究」です。
研究対象期間は2015年4月〜2017年3月 の24ヶ月です。
SGLT2阻害剤の発売は2014年4月・5月、9月等と、まだ新しく、ある程度期間を経てからの症例を対象とすることにしました。
選択基準は既に述べた通り、観察期間中に一度でも対象薬剤のいずれかが投与された患者さんとなります。(単剤処方のみ)
【対象薬剤:DPP-4阻害薬・SGLT2阻害薬・SU剤・ビグアナイド系】
除外基準・アウトカムの定義も右図の通りです。
【観察期間の定義】
下図のように設定しています。
1.糖尿病治療薬が最初に処方された日を、観察開始日とする。
2.曝露終了日もしくはイベント発現日を、観察終了日とする。(いずれか早いほう)
3.糖尿病薬治療薬の変更、または、28日以上の投与間隔があると、観察終了とする。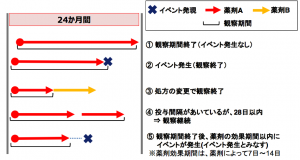
【曝露の定義】
下記の通り、上気道感染並びに尿路感染においてそれぞれDPP-4阻害薬とSGLT2阻害薬を曝露として
対照群を設定しています。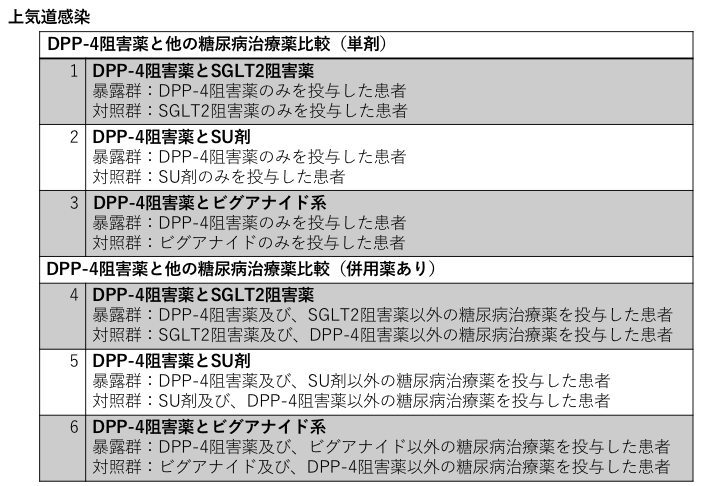

【アウトカムの定義】
・上気道感染
観察期間中最初に発現した日をイベント発現日としました。
ただし、観察終了後7日以内(ただし、トレラグリプチンとオマリグリプチンに関しては、14日以内)までに発現した症例は、イベント発現に含めています。
・尿路感染
観察期間中最初に発現した日を、イベント発現日としました。
ただし、観察終了後7日以内(ただし、トレラグリプチンとオマリグリプチンに関しては、14日以内)までに発現した症例は、イベント発現に含めています。それぞれ傷病名(コード)はICD10コードから該当するものを選択しています。(詳細は割愛)
【リスク因子の定義】
性別・年齢・HbA1C値・糖尿病重症度を設定しました。
糖尿病重症度の定義については右図のように合併症を対象基準としており、
該当する場合に「あり」としています。
年齢は、10歳刻みに整理、処方開始時の年齢を採用しています。
リスク因子の検討時は連続量として取り扱っています。
HbA1c値は連続量です。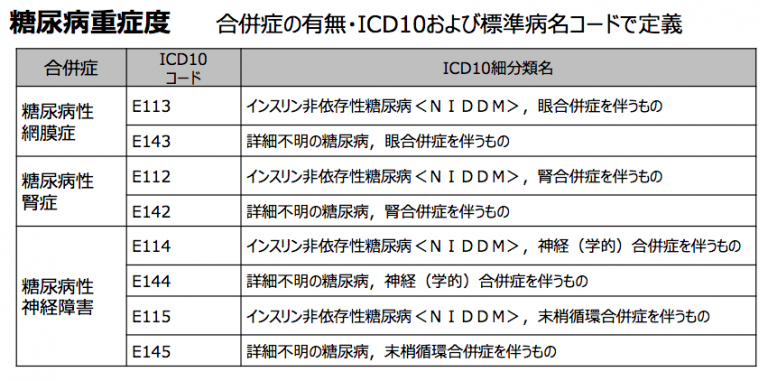
【統計的事項について】
下記を解析によって導き出し、リサーチクエスチョンに応えることを目指しました。
◆背景因子別の患者分布
暴露群、対照群、全体での背景分布を確認します。
背景因子:性別/年齢/糖尿病重症度/HbA1c値
◆感染症の発現率
暴露群及び対照群での感染症の発現率(人年法)と95%信頼区間を確認します。
「背景因子別の患者分布」での背景因子別の発現率(人年法)と95%信頼区間を確認します。
◆暴露群と対照群の感染症発現の比較
対照群に対する暴露群のハザード比及びその95%信頼区間、及びP値を出力します。
背景因子を調整因子として、Cox比例ハザードモデルによる多変量解析を実施し、
対照群に対する暴露群の調整済ハザード比及びその95%信頼区間、及びP値を出力します。
◆暴露群の感染症発現のリスク因子の検討
暴露群について、以下の検討を行います。
「背景因子別の患者分布」での背景因子、薬剤因子別の発現率(人年法)、
95%信頼区間及びハザード比及びその95%信頼区間、及びP値を出力します。
感染症の発現に関し、背景因子及び薬剤因子を調整因子として、
Cox比例ハザードモデルによる多変量解析を実施し、ハザード比及びその95%信頼区間、
及びP値を出力します。(ここまでで学んだ点・苦労した点)
当たり前ですが、研究計画上の定義付けが多くあり、一つ一つでメンバー間で話し合いが行われました。
定義による観察数低下への影響が常に気になるところでした。
会議のたびに定義を仮決定するのですが、定義付け後に発覚する”観察にむけての課題”もあり、
定義直しを繰り返しました。繰り返し最中には、医療データベースへの記載内容についてはその都度確かめながら、進めています。
観察時でのSQLと合わせて解析ロジックとの整合性を保つのは解析者にしか理解できない苦労があったかと思います。会議時に「これはどういうこと?」と、メンバーから質問が入り、
最初に行った定義付けとその結果出された内容への疑義が生じると、
定義変更につながるアイデアが毎度毎度ブレストのように参加メンバーから生まれました。
ご想像どおりですが、そのたびにSQLと解析ロジックの見直しが発生しています。
これを良しとするか、どうかは研究自体の目的にもよるかと思います。ここらへんは会議の進め方という組織文化や、研究スキーム策定方法という研究者としての経験値、力量も
大きく関係したかもしれません。
そもそもが皆、手探り状態での進め方だったのかと思います。例えば、重症度を示す傷病コードの選択・設定時においても、MDからのコメントは曖昧なままでした。
「重症度ってどのように設計しようか?」
「(糖尿病性)網膜症も腎不全も血管障害も重症です」
「まぁ、そうだよね」
「重症度の強さでランク分けするとどうかな」
「網膜症と腎不全が併発していたら、それは一番ランクが高いよね」
「そもそも腎不全は重症でしょ」
「どれも重症だからね」
こんな会話が飛び交っていました。
結局、明確な設計がすぐには出来ず、(医療関係者でも)
例えばこのコードで良いのかを、一つ一つ探るという基礎的なところからの検討でした。
後から追加となったものがあることは言うまでもありません。
単純な追加レベルであればそんなに苦労しませんが。この頃には「自主研究をシンポジウムにて発表する」という具体的なスケジュールが
決まっており、
統計的事項において導き出すものや、解析事項とするものに対しても時間的制約が生じ始めています。
いつまでも行ったり来たりができなくなりました。まさに時間との戦いですね。
会議のたびに複雑になる「観察の定義」に合わせて解析用プログラミングも複雑になりがちなので
そこらへんの苦しみも現場にはあったようです。
それについてはまた別稿にて。次回は結果について報告したいと思います。
タグ: -
お問合わせ
メルマガ登録

