データマイニングとシグナルディテクションについて
-
大規模データを対象として解析を行う際に意識すべきこの2つの言葉の概念を中心に説明します。
データマイニングについて
データマイニングの定義は各書・各サイトにて説明書きがあるかと思います。どの説明も否定はしませんが、私の考える定義は右図記載の通りです。
システムサイエンスの研究者であるRussell L. Ackoff氏が提唱したDIKWピラミッドというモデルでは非常にわかりやすい概念を教えてくれています。図を見るだけでピンと来ますのでご参考ください。意識するだけで研究推進力が変わるかと思います。
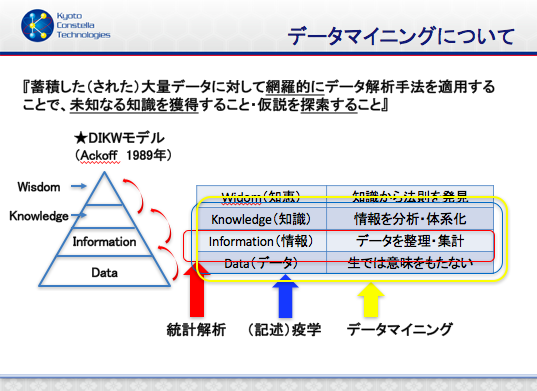
生のままでは意味をなさない大量データを価値あるものに変えられるのは、知恵や法則を導き出す手法があるからだという見方と、大量データを集めるからこそ新たな手法・手段を適用できる機会創出を生み出すという見方がありますが、終止符が打てないその論争はどちらも正解だと思いますのでここでは触れません。
既に集まったデータをどのように料理して新たな発見をするのか(二次利用)という視点と、仮説検証のために必要な情報(と不要な情報削除)の収集・解析という視点を併せて考慮することで統計解析のスタートを切ることができると思います。その中でもデータマイニングにおいて重要なことは「機械的」「網羅的」なデータ解析手法を適用するということに尽きるかと思います。
統計解析の手法自体を探索するという研究ももちろん重要ですが、再現性のある手法を適用でき、かつ迅速性にも対応できることがマイニングに求められるところだと日頃より感じています。同じデータバージョン・同じ手法で解析のたびに異なる結果がでるのは信頼性にかけます。ところが、データバージョンが異なり(新しいデータへと更新され)同じ手法を適用すると新しい知見を見つけることができることもあります。定点観測による新発見です。また、定点観測時に毎回多大な時間を浪費するわけにもいきませんし、新発見時に異なる手法を試し、新たな視点による観測を開始したときに更なる時間の浪費をするわけにもいきません。新発見をした時は、いろんな視点を加えたい欲望に駆られ、往々にしてこの手の罠にハマりがちです。その為には実はデータ側(データベース側)にも求められる要素は多くあり、生の情報が適当に収集されて、抜けがあったりミスが多かったりすると価値を生み出す土壌にもならない可能性が大いにあります。そしてもちろんデータ収集には”継続性”が求められます。
そう考えるとデータ側の整備方法や、解析に耐えうる収集項目の設定に関しても深く足をつっこんで関与することが、データマイニングにとって重要であることが理解できるかと思います。
例えば層別分析を対照がないDBに適用して失敗したり、影響因子を考慮せずに結論を出して失敗したりと経験はないでしょうか?右図はデータマイニングをさらに系統的にわけた場合の記載です。
テキストマイニングという”言葉”を分析する手法が昨今重要視されていますのでこの図式も概念としては分かりやすいかと思います。ただ、上述したように、重要なプロセスであるデータの整備手法まで含めてデータマイニングと定義することももちろん有りえるかと思います。
手法が進化すればするほど、昨今注目を浴びるAIにも好影響をもたらすでしょうし、生のデータから知恵を生み出すために加速をしてくれるものもAIだと思われます。データが少なくてもサジェストできるという技術もあるようなので、概念図を日々改良させないと技術に追いつかない、技術を的を得て説明できなくなっています。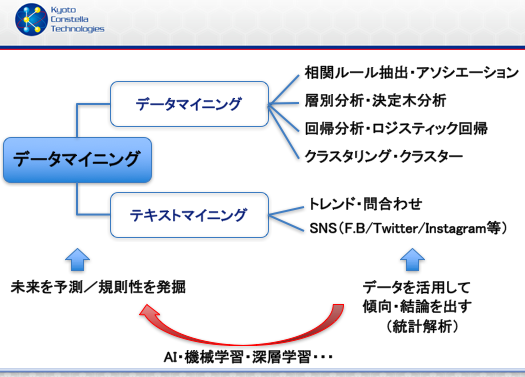
シグナルディテクションについて
本ブログの対象領域でいうと、
”シグナル”とは
『それまで知られていなかったか、もしくは不完全にしか立証されていなかった有害事象と医薬品との因果関係の可能性に関する情報』となります。(WHO定義)”シグナルディテクション”は、「シグナルを探索すること」という意味です。
上述したデータマイニングの節でも、DIKWモデルにおいては同義となるかと思います。シグナルを拾い上げる、シグナルとして見つけることを
”シグナル検出”といい、
シグナル検出によって、さらに詳細な調査を必要とする副作用報告の発見及びその優先順位付けを行うことにつながります。
広い意味では、臨床現場において、医療従事者が診療行為や文献調査で未知の副作用発見をすることもシグナル検出となります。
データマイニングの世界においては、機械的・網羅的に副作用候補を発見することです。FAERS・JADERのように自発報告有害事象データベースを対象としてデータマイニングを行う際には、注目する医薬品の使用された全体の患者数は分からず、「有害事象がある症例レポート群」を対象とするため、その中から「副作用として怪しげだな?より深い調査をする対象とする」ものを見つけることがファーストステップの探索となり、そのためには不均衡分析を実施することが一般的です。不均衡分析では、設定群を「注目薬剤における各有害事象の全有害事象に対する報告割合」とし、対照群を「全薬剤(その他薬剤)の全有害事象に対する報告割合」とし、設定群VS対照群を比較して違いを見つけます。

不均衡分析を行う際には全症例レポートに記載されている全薬剤と、全有害事象をカウントして、
それを2×2の分割表に落とし込んでから計算をします。
統計ソフトで自動的にやってもらえるところですが、データのコーディングや、テーブル設計、検索ノウハウや、重複削除設定等細かい考慮は必要です。・どんなプロセスで集計されているのか?
>どの条件で検索、計数をしているのか?
>どのカラムを対象としてカウントしているのか?
・設定群と対照群で設定条件に異なることはないか?
(>調整の必要な因子はないか?)
など、初めは意識して進めたほうがよいかと思います。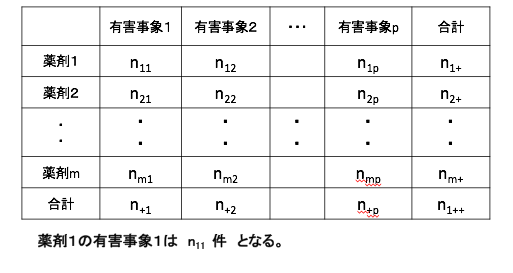
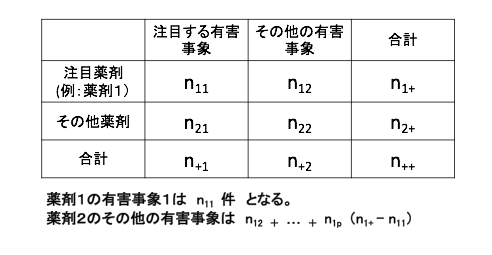

分割表に落とし込めればスコア指標の計算です。
PRR・RORといった代表的なスコア指標が論文でもよく用いられています。
また、各指標における閾値が設定されており、その閾値を超えれば”シグナル検出”となります。その指標の意味、閾値の設定の意味などを理解されたい方は下記論文を参考ください。
PRR:Evans, S., Waller, P. and Davis, S.: 2001, Use of proportional reporting ratios (PRRs) for signal generation from spontaneous adverse drug reaction reports, Pharmacoepidemiology and Drug Safety 10(6), 483–486.
ROR:Euge`ne P. van Puijenbroek*1, Andrew Bate2,3, Hubert G. M. Leufkens4, Marie Lindquist2, Roland Orre5 and Antoine C. G. Egberts4:
A comparison of measures of disproportionality for signal detection in spontaneous reporting systems for adverse drug reactions,pharmacoepidemiology and drug safety 2002; 11: 3–10代表的シグナル検出手法を下記にテーブル表示します。
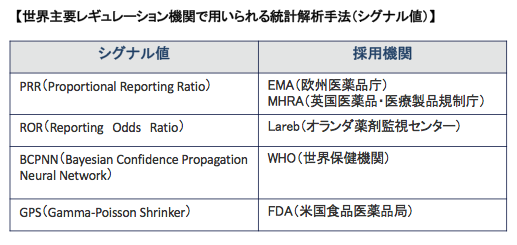
有害事象データベースやこのデータベースに対して実施する不均衡分析については『過少報告、曝露データ不足、バイアスの存在、ウェーバー効果等
報告件数の少ないJADERでは95%CI幅が大きくなり、シグナルが認められにくい。』という注意事項が存在します。論文上でも考察によく同様の記述が認められます。
参考ですが、
「抗癌剤を対象として解析、ウェーバー効果は存在しない」
Arora, Ankur,et al. Therapeutics and clinical risk management
Relevance of the Weber effect in contemporary pharmacovigilance of oncology drugs.
「リアルワールドデータによる観察研究 の結果は,主要評価項目についてランダム化比較試験に遜色ない傾向を示す」
Dahabreh IJ, Kent DM, Can the learning health care system be educated with observational data? JAMA, 2014, 312, 129-130.
といった主張も出始めています。まとめ
★データマイニング
二次利用における意識だけでなく、データ収集”継続性”・整備(”迅速性に貢献”)にも目を向ける
日常解析モチベーションを下げないためにも速度は重要、解析手法は機械的・網羅的な適用を意識する
★シグナルディテクション(シグナル探索・シグナル検知)
有害事象データベースにおける不均衡分析(disproportionality analysis)を用いて実施される -
お問合わせ
メルマガ登録



