DB構造について FAERS版
-
※FAERS は 2026年3月11日より AEMS に移行・統合されました。
FDA Launches New Adverse Event Look-Up Toolリアルワードルデータベース(RWD)と言われる『医療データベース(DB)』を対象とした研究、解析が重要視されています。2018年4月からはMID-NETの本格稼働が始まり、色んなシーンで医療DBの活用が求められてきます。
薬剤疫学という分野において、各種医療データベースの構造について理解しておくことは必ずプラスになります。
本稿ではFAERSのデータ構造に触れながら概念を中心に説明します。
細かい構造や内容についてはJADERのほうが分かりやすいので、JADER版にてお伝えします。(参考2)FAERデータのダウンロード場所について
FAERSのデータはFDAのHPから無料でダウンロードできます。
FDAホームページ内の
>Drugs >Guidance, Compliance & Regulatory Information >Surveillance> FDA Adverse Events Reporting System (FAERS)の場所にあります。(直リンクは避けます)「Latest Quarterly Data Files」を見つけてください。
HP内の検索ボックスで「FAERS」と打てばすぐに検索できるかと思います。余談ですが、検索エンジンで「FDA」と検索してもアメリカ食品医薬品局は検索トップには出てこないかもしれません。
某航空会社のページがトップに来るかもしれません。
その場合は ” US FOOD and DRUG Administration ” を検索してみてください。JADERと違い、差分が各四半期でアップされますので解析するためは
過去分の全データをダウンロードする必要があります。(古いものは有償で別機関が販売)
構造は記載内容が年度によって異なる箇所もあるので注意が必要です。
特に2014年の第3Qから大きく変更していますので、それまでのデータと統合して解析するには
細かいところを確認しなければなりません。そういうときにはFAQやQ&Aが役に立ちます。
ボリュームのあるデータだけでなく、こうしたFAQがあるのも心強いところです。
(本稿においては現時点での最新版をもとに説明します)一般的にデータベースには”テーブル”と言われる行と列によって構成される表が複数あります。
その複数の各テーブルに意味のある情報が記述されています。
それぞれの行はレコード、列はフィールドと言います。一つのテーブル内のレコードには
一貫性のある方法で情報を組み合わせています。フィールドでは、その中の一つの項目を示します。FAERSのドラッグテーブルの中には薬に関する情報が含まれています。
いくつか挙げます。
◯主キー
◯薬の連番号
◯役割
◯薬剤名
◯(製品名)
◯投与ルート
◯用法用量
◯ユニット
◯投与を止めたかどうか
◯再投与したかどうか
等です。これらの情報をみると
「では、その薬をいつ飲んだのか?どのぐらい飲んだのか?飲んだ後、いつ、どんな有害事象が発生したのか?」
という疑問がすぐに生まれないでしょうか?
また、DB構造を知るという目的では、その情報がどのテーブルに記載があり、どのようにリンクされているのかが知りたくなるのではないかと思います。その前に情報のソースについて説明します。
本投稿では「DBの構造について」というタイトルゆえに整備されたデータベースがある前提で説明を始めましたが、
そもそも収集されている情報ソースがどのようなものであるのかを確認する必要があります。実際に副作用報告をしたことがある方は分かるかと思いますが、症例報告レポートとしては
1症例で1枚の報告用紙になります。(実際には数ページありますが)
この用紙は日本で言うと、『医薬品安全性情報報告書』と言われ、
医薬品医療機器等法に基づいた報告制度です。
PMDAのHPからダウンロードできます。
リンクはこちらを参考ください。(pmda.go.jp/safety/reports/hcp/0001.html)
製薬企業のみならず、医療従事者からの報告も法律によって定められています。規制機関によって若干報告様式・項目が異なります。
その違いが、データベース構造やフィールドの違いによって現れます。この報告が収集(FAERSは年間120万件超)され、整理された後データベース化されます。
その整理される時に、薬に関する情報はドラッグテーブルに、副作用に関する情報はイベントテーブルにというように
一貫性をもって細かくわけられるようになります。この報告、収集される情報はまさしく薬の安全性に関する評価を利用目的とするため、
投与された患者さんの情報(demoテーブルと言われます。もちろん個人情報は特定されません)、
薬の情報(ドラッグテーブル)、副作用/有害事象の情報(イベントテーブル)、原疾患の情報(インディケーションテーブル)などに分かれます。
そしてそれらを結びつけるための主キーとして症例番号(ISR)が用いられます。例えば症例番号001という副作用報告情報では
Demoテーブルにおいて
001,男性,65歳(老年という記載も),165cm,67kg
ドラッグテーブルにおいて
001,アスピリン,0.5mg,経口投与,第1被疑薬
リアクションテーブルにおいて、
001,発疹,2017年07月1日(発症日)
001,手足しびれ,2017年07月1日(発症日)
セラピーテーブルにおいて
001,2017年6月1日(投与日),2017年6月15日(やめた日)
原疾患テーブルにおいて
001,頭痛のように分けられて整理されます。だいぶ簡単に書きました。
FAERSのテーブル構成は下図のようになっています。
説明用ファイルから抜粋しています。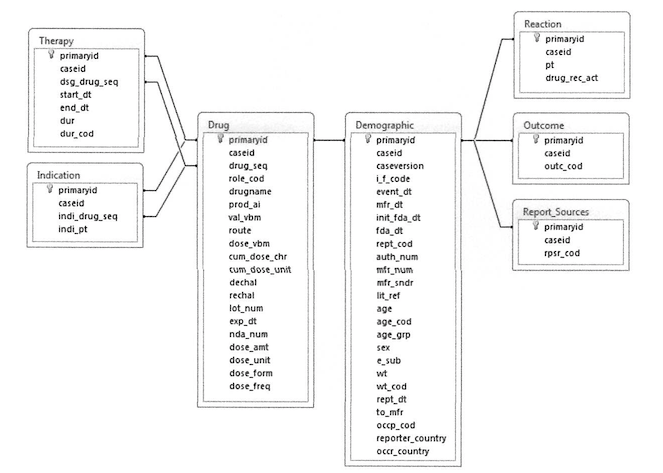
そういった整理された情報を用いると先程浮かんでいた疑問「では、その薬をいつ飲んだのか?どのぐらい飲んだのか?飲んだ後、いつ、どんな有害事象が発生したのか?」にすぐに応えられます。
◯いつ飲んだのか?
:Therapyテーブルから飲んだ日(投与日)を確認◯どのぐらい飲んだのか?
:Drugテーブルから用法用量を確認◯飲んだ後、いつ有害事象が発生したのか?
:Demographicテーブルからイベント発生日(他、企業への報告日やFDAへの報告日などもあり)を確認◯どんな有害事象が発生したのか?
:Reactionテーブルから(イベント情報を確認)他にも
◯転帰は何?
:Outcomeテーブルから転帰情報を確認◯情報源は?
:Report_Sourcesテーブルから報告者・情報ソースを確認などがわかります。
主キーを用いて別テーブルの情報を参考にすればすぐに答が見つかります。このテーブルの存在と構造が理解できればデータベースを知るには十分です。
・どのようなテーブルが存在するか?
・各テーブルにはどのようなレコードやフィールドがあるのか?
を確認すれば大きく内容を紐解く事ができるかと思います。
集められるソース(1枚の安全性情報報告書)の各項目を目を皿のようにしてみても
DB側で整理されているレコード・フィールドを確認しなければ何を変数とすればよいのかが
わかりませんので、上を意識することが重要かと思います。
観察研究において目的とする変数が見出されてから疫学的研究に進む場合でも構造を理解することは重要です。また、そこまで理解できれいれば、
各統計ソフトを用いて解析をスタートさせることが出来るかと思います。
プログラムを組む必要のない便利な統計ソフトの場合だとデータベースファイルを読み込めば
フィールドが自動的に選択できるようになるかと思います。
独立変数を選択すればロジスティック回帰分析等について、すぐに結果を出してもらえますし、
バブルチャートなど各種ビジュアル系グラフも自動的に作図してくれるものもあります。
因果関係指標にもなるP値の計算まで出してくれるものものまであります。そうすると、
・転帰情報を頼りに重篤な結果となった症例だけを対象として解析してみたい
・投与から1ヶ月以降に発症した症例だけを解析してみたい
という視点での解析ニーズも出てこないでしょうか?ただし、これだけでは不十分でもあります。
理由はいくつかあります。
◆各DBの構造差異の理解が必要
これは今後医療DBが複数注目されることを考慮するとその必要性がすぐに理解出来るかと思います。
◆DB記載内容の情報を吟味した上で、対応が必要
・テキスト情報
解析ソフトはテキストマイニングに特化していない限り文字情報には弱いです。
単純ですが、腸閉塞を腸と閉塞にわけて解析されてしまうケースもあります。
小腸閉塞と大腸閉塞をわけて解析したい時に対応してくれません。
56歳と数字のようで文字の場合もありますし、”成人”と記載されている場合は文字です。
文字情報を含んだ解析はとにかく重いと思ってもらっていいです。PC負担が大きく、落ちることもあります。
・コーディング
MedDRAはご存知でしょうか?世界標準となっている用語はコーディングのため導入は必須です。
薬剤辞書についても重要です。
・記載情報の正確性、空白率
報告日を8桁(年月日)で記載しているとは限りません。
空白率が高い変数を対象とするのはお勧めできません。
これらについては別途投稿予定です。
◆DB成り立ちの目的
薬剤と副作用の因果関係を調査したいのに、副作用テーブルがないDBは利用ができません。
収集目的と調査目的が一致しないとすぐには活用できません。
◆ビッグデータ解析に必要な環境
FAERSは1000万件を超えているビッグデータです。
家庭用PCと廉価な市販統計ソフトでは単純なカウントや簡易な計算以外、なかなか解析できません。
しかもデータ量は年々増加傾向なので、CPUの性能アップがムーアの法則外となった今、
技術革新によるデータボリュームへの対応は期待しないほうがよいかと思います。スパコンは別ですが。
などなど。多くの方はこの後半部分の”理由”に関しては関係ないかもしれません。
ただし、大規模データ解析・集団でのデータ判断を行うケースは多くなるかと思います。
そういったケースが増えると解析視点もより多種多様になる可能性が大きいです。
たとえば医療DBとして一種類だけでなく、公的DB・商用DBなど複数のDBを用いて解析をする場合などは
やはりその構造を理解しておいたほうがいいというのは言うまでもありません。最近ではWeibull解析という手法で、薬の投与期間を割り出して投与からイベント発生までの期間を
解析としている研究報告も増えてきました。
これはテーブル構造を理解していれば高いハードルなく出来る解析だと思います。
ただし、DB記載内容の情報を吟味しているからこそ各研究者はFAERSではなく、JADERを対象にしているのだと思われます。ちなみにですが、
CzeekVでは、「簡便に、検索をするだけで、くすりと有害事象の因果関係を疫学的ベースな知見で(スコア値等)探索できる」
という目的を果たすために、システム設計とDB構造設計を行いました。
特にDB構造については「できるだけRawデータのままを提供できる」ことを目標として、
社内で数段階にわけて正規化したDB構造としています。FAERS・JADER(もしかすると他の医療DBも)の構造が変われば対応した形となるよう邁進する予定です。開発者としては戦々恐々ですが。
-
お問合わせ
メルマガ登録



