既報/未報(既知/未知)機能 について②
-
本稿では
「既報/未報(既知/未知)機能 について①」の続きとして、
関係する研究について過去に学会ポスター発表したものについて報告します。タイトル
副作用用語の網羅的マッピング技術による有害事象自発報告の既知未知分類
背景・目的
有害事象検証の一つの方法としてシグナル検出結果と添付文書記載内容を比較することで知見を得ようとすることはイメージしやすいかと思います。
しかし、ターミノロジーが異なる添付文書と自発報告の副作用用語は容易に比較できません。
そこで本研究では、自発報告で用いられるMedDRAと、添付文書の副作用用語を網羅的にマッピングし、
有害事象の既知未知を自動的に判定できる仕組みを構築し、評価を進めました。
研究を進めるにあたって重視したのはいかに網羅的かつ精度高くマッピングを施せるのかという視点です。方法
JADER・FAERSを準備、キュレーション、コーディングを行い、
重複削除はFDA推奨方法をもとに実施しています。
この時、薬剤は成分ごと、有害事象はMedDRAを用いており、
PT・HLT・HLGT・SMQ(狭義)の階層でシグナルを検出しています。
スコア指標はRORを採用、シグナル検出基準はROR95%信頼区間下限値が1を超え、かつ症例数が3以上のものとしました。
(件数はPRRと共に用いられる閾値ですが、あえて加えています)添付文書内「副作用」の項目から、形態素解析エンジンMecabを用いて機械的に抽出した添付文書副作用用語に対して、
表記ゆれを考慮したマッピングツール「MedMapp?」((有)ティ辞書企画)を用いて、網羅的にMedDRAと結び付けた
シグナル検出の有無と添付文書記載の有無(既知未知)を比較しました。下準備
=添付文書からの副作用用語抽出=
副作用用語の偏りが小さくなるよう、製造販売会社や成分の異なる薬剤を、ランダムに30薬剤選び、
自動的に抽出した副作用用語が、「副作用」の項目から、洩れなく抜き出せていることを確認しました。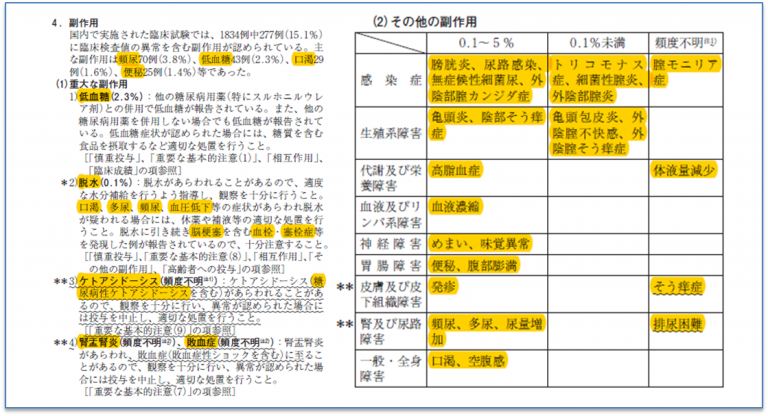
マッピング内容
添付文書副作用用語とMedDRAのマッピングについて
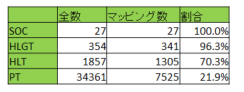
添付文書副作用用語7,992語のうち、MedDRAのPT/LLTに完全一致した用語は、3,936語(49%)でした。
部分一致は、3,719語(47%)でした。
一方、MedDRA22,499語のPTのうち、添付文書副作用用語に完全一致した用語は、2,778語(12%)で、
部分一致は、3,816語(17%)でした。つまり、添付文書副作用用語は、96%がMedDRA用語にマッピングできたのですが、
MedDRA用語から見ると、PTの22%しかマッピングできない結果となりました。MedDRAマッピング状況
階層ごとにマッピング率を見ると、右テーブルのようになっています。
=階層ごとのシグナル検出数と既知未知の割合=
PT・HLT・HLGT・SMQそれぞれの階層でシグナルを検出し、マッピングにより紐づけられた副作用用語が添付文書に記載されている有害事象を”既知”としました。
(HLT・HLGT・SMQは、下位のPTが既知であるものを、”既知”)
成分毎に、「全有害事象数」「そのうちのシグナル検出数」「添付文書に記載されている有害事象数」「そのうちのシグナル検出数」を出し、その平均と割合をテーブルに示したものが右側のものです。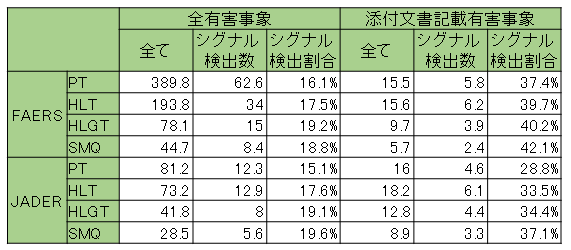
結果と考察
=添付文書からの副作用用語抽出について=
(結果)
広範囲の副作用用語が抽出できていることを確認出来ました。・考慮すべき点
副作用の情報は、添付文書内「副作用」の項目から自動抽出しましたが、
ご存知の通り副作用情報は「副作用」項目以外にも記載されています。
ただし、抽出範囲を添付文書全体に広げてしまうと、
副作用ではない用語まで抽出される可能性があり添付文書そのものの構造へも注意を向けたほうが良いかと考えられます。
(※2017年時点ですのでXML版の新添付文書構造を考慮していません)今回の抽出方法は、「副作用用語が現れるか現れないか」という視点で判断されており、
否定形・係り受けなどの文脈は考慮していません。
辞書の性能は問題ないと思われますが、上記等も踏まえてテキストマイニング技術を向上させ、
適切な副作用のみを抽出することを今後は目指していきたいと考えています。=添付文書副作用用語とMedDRAのマッピング=
(結果)
添付文書副作用用語の96%が、MedDRA(PT)にマッピングされていました。MedDRAのPTは、「企図的製品誤用」「適応外使用」「法律問題」「有害事象なし」など、そもそも添付文書に載らないような用語もあります。
右にFAERSが報告数が多くかつJADER報告も考慮してマッピング出来なかったPT用語の上位リストをあげます。
これら「添付文書に載らない用語」を除外して、マッピングの性能を評価すると更に高い精度の%が出るかと思われます。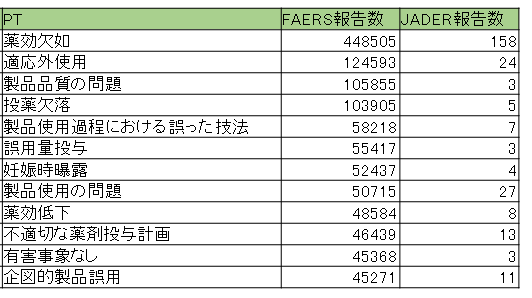
また、FAERSに比べてJADERは、重篤な有害事象の報告が多い傾向があるため、
「FAERSで報告が多いが、JADERで報告されないPT」は、
添付文書に載らない用語である可能性が高いと考えられます。=階層ごとのシグナル検出数と既知未知の割合=
(結果)
添付文書への記載有無を網羅的・自動的に判定することで、シグナル検出された有害事象に優先順をつけて
絞り込むことができるようになりました。
全有害事象と、添付文書における記載がある有害事象では、FAERS・JADERともに、
後者の方がシグナル検出割合が高かったです。
また、PT, HLT, HLGT, SMQの階層の違いで見ると、FAERS・JADERともに、
この順でシグナル検出の割合が高い傾向にありました。
全有害事象のうち、添付文書に記載されている有害事象の割合(既知率)は、
PT, HLT, HLGT, SMQの順に高くなり、JADERの割合の方が高かったです。(考察)
FAERSとJADERの既知率の違いは、報告に使用されるPTの多様性の違い・内容の違いによるものと考えられます。
PT22,499語のうち報告に使用されるPTは、FAERS:18,194語・JADER:8,024語と、
FAERSの方がバリエーションが多い傾向が見受けられました。
(JADERは重篤な有害事象が多いことが知られおり、内容の違いに影響を与えているかと推察します)添付文書に記載された有害事象の割合がJADERにおいて高いのは、分母が小さく、
重篤な有害事象の報告が多い(=添付文書に載りやすい)ためと考えられます。
階層による既知率の違いは、PTの多様性によりマッピング過程で「似ているが異なる」と判定された類似のPTを、
上位階層でまとめることができたためと思われます。
マッピングの部分一致対象を広げるほど、関連性の低い用語まで紐づけてしまう恐れがあるため、
マッピングの精度は狭く・鋭くし、MedDRAのグルーピング(上位階層やSMQ)と組み合わせることで、
「PT用語の揺らぎ」を吸収するのが良いと考えられます。参考情報
=添付文書副作用用語とMedDRAのマッピングについて=
マッピングされなかったPTのうち、JADERの報告が10症例以上あるPTは、5%程度でした。
つまり、マッピングされなかったPTの95%は、JADERでの報告数が10症例に満たない、使用頻度の低い用語であると考えられます。参考情報
=添付文書記載副作用の自発報告の有無の傾向について=
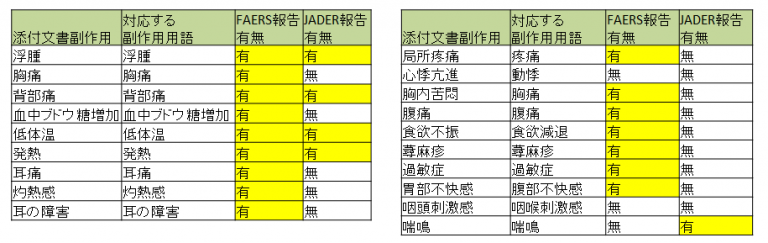
添付文書記載の副作用に対応する副作用用語において自発報告有無を調べてみたところ、
FAERSの方が報告されている割合が高い傾向にあり、未知の有害事象報告もJADERより多いようです。
FAERS報告の多様性にも一因があると考えられますが、
JADERにおける、添付文書に記載されている事象(特に軽症のもの)は、
既知のものとして報告しない傾向にあったり、公開時点においてスクリーニングされている可能性があるものかと推察されます。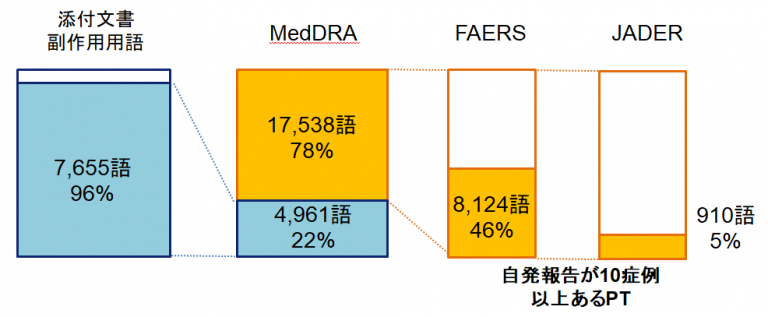
まとめ
■網羅的なマッピングを精度高く実施
精度については、マッピングに不適切な用語等も考慮する■DBの特性によって報告内容には注意が必要
■副作用用語とのマッピングを検討することで
多くの注意事項の見識を広めることが出来ました。■既報未報(既知未知)を、シグナルディテクション/臨床現場への活用につなげたい
-
お問合わせ
メルマガ登録



