副作用用語について 〜後半〜(CzeekV実践)
-
前半では副作用用語についての基本的な情報を紹介しました。
後半では追加の基本情報も紹介しつつ、「CzeekVではどのようになっているのか?」「解析時にどのような方法が考えられるか?」
について述べたいと思います。また、
・ある時期にいきなり件数が増えているが、バイアスではないか?
・(CzeekVのDB更新時シグナル検出機能を使ってみると)前月まで0件だったのにいきなり数十件も報告があるが本当か?
の質問への回答も忘れないように記述していきたいと思います。前半でも説明したMedDRA用語ですが、半年に一度、アップデートされます。(3月・9月)
階層構造になっているとも説明しました。
パンくずリスト的に記述すると
SOC > HGLT > HTL > PT > LLT となっています。公開されているDBにおいては、(JADER/FAERSともに) 副作用は”PT”で記述されています。
一方、当局では「副作用報告はLLTで用語選択をしてください」と定めています。つまり、当局内では、収集した症例報告をDBとしてコーディングする時にLLTから該当するPTに変換して
(もしくは用語がない場合は該当すると思われるものを選択して)
公開用のDBを整備していることになります。で、半年に一度のアップデートです。
この時、LLTからPTへの格上げ・PTからLLTへの格下げ が”よく”行われます。
(頻繁の定義は難しいですが、私としては感覚的には「よくあるよね?」と思っています。)
余談ですが、
SJSもスティーブンス・ジョンソン症候群からスティーヴンス・ジョンソン症候群と
「ブ」から「ヴ」への記述変更がありました。このように文字の変更も頻繁に行われています。我々は、あくまでも公開されているDBに記述されていれる「PT」に対してコーディング作業をしています。
例えば最新版のMedDRAを用いることで、
つまり、新しいバージョンのMedDRAを摘要することで、
今までなかった用語が新たにあたるようになり、
あたかもその時期にいきなり報告が多く出てきたように見えるケースもあります。この時、過去からその報告が継続して出ていることもあれば、
過去は全くの0件で、いきなり多数報告があるケースもあります。
JADERは差分だけの公開ではなく、過去分もすべて一新されたDBの公開です。
FAERSは差分だけの公開です。これらの公開スキームも影響しています。
過去にあたらなかった用語があったり、その逆もあったりします。
(JADERもFAERSも摘要しているMedDRAのバージョンはReadmeなどに記載されています。)こういった事情を加味すると、
解析時には、全てをバイアスのせいにするのではなく、ヒストグラムなどを活用して
注目した薬剤と副作用の報告がどのような経緯であったのか?をみる観察の目が必要かと思います。また、PTが所属する上位階層グループでクラスタリングするという手法もあります。
SOC以外にもSMQというものもあります。SMQについて
SMQ:「Standard MedDRA Queries(MedDRA 標準検索式)」とは、
MedDRAのPTを特定の医学的状態に関連付け、グループ化したものです。
このグルーピングでは、症状や徴候、医学的初見などが関連付けられている構造を持ちます。最近の研究ではPTだけを解析するのではなく、SMQを活用したものも多く報告されています。
・SMQで傾向を掴む、その後PTでより詳細を確認する。
・PTで検知したものに関してSMQでも全体傾向の確認を進めるといった使われ方がされています。
残念ですが、著作権に抵触する可能性があるので具体例を記載出来ませんが臨床研究者には注目されています。さて、CzeekVにおいては、どうなっているのか?を説明します。
搭載しているDBは最新版にあわせて設計、キュレ−ションを実施しています。
JADERではReadmeに記載している「MedDRA Ver.」の情報を参照し、同じ版でのコーディング作業を実施しています。
前月まで検索に引っかからなかった用語が新しく検索できるようになるのは
・PTに新しい用語が含まれるようになった可能性
・JADER上で過去分も含めて更新されてから公開された可能性
があり、
LLTからPTへの格上げも疑います。いずれにせよ、検索するほど注目している用語であれば
かならずヒストグラムで傾向を確認することはされたほうがよいかと思われます。あるケースでは、「症例報告レポートの中に今までは記載がなかった症状が新しく記載されている」といったことも有りえます。
モニタリングを目的としているのであれば、DB更新時には必ずチェックしたほうが良い理由の一つです。参考
DB更新時のシグナル検出機能について
(この機能での前月のカウント数は、前月までのバージョンでのカウントです。)特にまだ因果関係のわからないものや、未知の副作用が検知されたときは
バージョンの影響なども考慮したほうが良さそうです。
DB研究共通して言えることになります。こうして副作用(有害事象)用語の基本的な情報を整理したり、
DB研究を目的としたコーディングプロセスを確認することで
辞書・ターミノロジーの役割・重要性が改めて意識できたのではないでしょうか?仮にこの辞書に「血圧上昇」がなければ解析のソースたる症例報告DBには記述があったとしても、
この症状が拾えなくなります。
検索できなくなってしまう、カウントしても0件という統計情報が解析結果として出てしまうことになります。
(生DBにはあるのに、解析用にコーディングする時点で削ぎ落とすという失敗例を避けることは常に考えないといけません)このことから
医療DB研究を行うときには、
「DBの版(バージョン番号・いつ公開されたものか?)」だけではなく、
そのDBに適用した用語集(辞書・ターミノロジー)のバージョンも
(再現性のためには)保存する必要が理解いただけるかと思います。
同じDB版に、異なる用語集の版を適用しても同じ結果を得られるとは限りません。
逆に、同じDB版・同じ用語集版であれば同じ解析メソッドであれば必ず同じ結果を得られるはずです。現時点でのCzeekVでは、全PTレベルでの計算を実施した情報を搭載しています。
MedDRAでの上位階層については計算はしておらず搭載していません。(SMQも搭載はしていません。)
あるPTについてその表現や内容に疑問が生じた場合には、似た表現の他PTでの報告を参考にするか、
関連性の高いPTをまとめてカウント値に入れるといった解析メソッドが考えられます。
その際、どのPTを拾うべきかについてはご相談ください。例えば”出血”に関する副作用用語も多くあります。
自身が注目する薬剤で検討しておきたい様々な”出血”を見ておく必要があります。下図のように、分割表のカウント設定によって解析メソッドが様々考えられます。
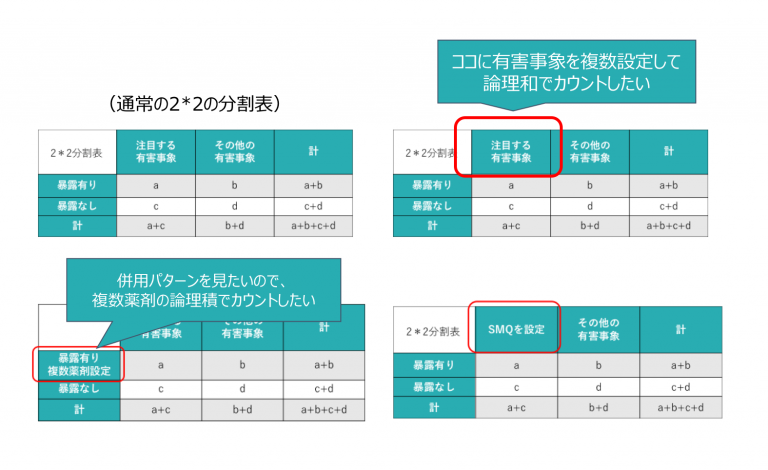
以上から、ある時にいきなり増えたPTだけを追いかけるのではなく、
その周辺情報も含めて解析を進めることも一つの手と言えます。
もしかすると、過去から報告があるものの可能性もありますし、
SMQでまとめてみると全体としては微増だったという可能性もあります。DBの特性として知っておいたほうがいい情報として副作用用語を中心に説明しました。
他に構造についても知っていれば理解が深まります。参考 DB構造について
DB構造について(JADER)
DB構造について(FAERS)(まとめ)
・PT←→LLTはバージョン更新で変わることが度々あります。
・研究の再現性にはDBの版だけでなく、ターミノロジーの版も保存が必要です。
(コーディングした薬剤辞書も含めます)
・解析対象としてのPTをまとめて論理和で設定する(上位階層該当のPT等)研究も進められています。
このことで用語に対する不安を払拭することもできます。(参考)
・パンくずリストとは 大分類>中分類>小分類 のようなリスト表記のことです。
(ヘンゼルとグレーテルが由来だと言われています。「ホーム」に帰る)
メジャーな用語ではないようですが知っておいて損はないと思います。(告知)
・PTをまとめてみたい といったニーズに対応した新機能を2018年9月オープン予定です。
乞うご期待を!(付記)
副作用用語については手持ちの統計ソフト上でテキストで検索する場合には
解析前のコーディングプロセスは不要ですが、
対象としたDBの版は必ず控えるようにしましょう。 -
お問合わせ
メルマガ登録



